12.4.1 键的输出顺序
Python中的字典类型基于哈希表,在Python3.6版本前,字典中的键的输出顺序取决于键在哈希表中的存储顺序,从Python3.6版本以后,字典中的键的输出顺序按其插入的先后顺序进行输出。
Python字典类型的底层实现正是基于哈希表。
代码实例:
# __desc__ = 测试字典的键的输出顺序
book = {"name": "108节课彻底学通Python", "author": "薯条老师"}
for _ in book:
print(_)
"""
Python3.6后版本的程序输出为:
name
author
"""
"""
Python3.6前版本的输出可能为:
author
name
"""12.4.2 键的数据类型
字典中的键的数据类型必须是不可变的数据类型,迄今为止学过的不可变数据类型有:简单数据类型,字符串,元组。同学们可以在交互模式中进行验证,使用列表类型和字典类型来作为字典的键:
>>> container={[0]:0}Traceback (most recent call last):File "<stdin>", line 1, in <module>TypeError: unhashable type: 'list'>>> container = {{1:1}:1}Traceback (most recent call last):File "<stdin>", line 1, in <module>TypeError: unhashable type: 'dict'
从交互模式的输出中可以分析出,在使用列表类型和字典类型作键名时,抛出了类型错误的异常信息:列表和字典类型是不可哈希的类型。同学们可以继续在交互模式中测试其它的动态的数据类型,同样会抛出类型错误的异常信息。
12.4.3 字典的快速查找
字符串,列表,元组是一种线性的顺序表结构,在不对顺序表结构进行任何处理时,对元素进行查找需要从头到尾地遍历。
举个简单的例子,下图表示一个包含5个数字的列表:

在列表中查询数字4时,由于4位于列表尾部,所以需要比较5次。
代码实例:
# __desc__ = 在列表中查询指定的数字 numbers = [5,2,3,1,4] number = 4 # 定义index变量,保存元素在列表中的索引 index = 0 # 在循环中遍历列表中的元素,逐一进行比较 # 如果列表中的元素与待查找的元素相等,就执行break退出循环 for _ in number: if number == _: break index += 1 else: # 如果是正常退出,说明元素不在列表中 index = -1假设列表中包含1百万个元素,那么按这种方式来查找,最慢需要比较1百万次,才能判定元素是否存在于列表中。由此可分析,当数据量很大时,使用列表等序列结构来进行元素查找,效率十分低下。
在对序列结构先进行排序以后,可以利用二分查找算法来执行快速地查找,在讲解到函数处理时,会教同学们彻底掌握二分查找算法。
字典类型采用哈希表进行实现,在理想情况下,只需计算一次键名的哈希值,就可以快速地查找元素是否存在于数据集合中,即使数据集合中存在百万级,甚至千万级,亿万级的数据量。
在计算键名的哈希值时会出现冲突,所谓的冲突是指多个键名具备相同的哈希值。冲突越大,查找性能越低,在极端情况下,字典的查找会退化为序列结构的慢速查找。
理解哈希表为什么查找速度这么快,同学们需要先学习哈希表结构。系统地学习哈希表结构,同学们需要掌握数据结构与算法这门课程,薯条老师同样会推出教同学们彻底掌握数据结构与算法的教程。
12.4.4 哈希表结构
下图所示为一个简单的哈希表结构:
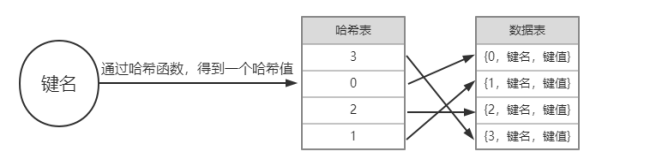
哈希表中的索引编号即为键名的哈希值,表单元中存储了数据表中的索引。在数据表中通过索引可以快速定位数据表中的数据单元,数据单元存储了键名与键值。
查找字典的键值时,Python会先计算键名的哈希值,通过该哈希值可定位到哈希表中的表单元,再取出表单元中的数据表索引编号。取到数据表索引编号后,再快速定位到数据表中的数据单元,以比较键名是否相等,如果相等,就取出键值。
哈希值是通过哈希函数将键名进行映射后的数字编号。为实现快速的查找,只需知道这个数字编号就行了。例如在字典对象book中,先计算键名author的哈希值,假设映射后的哈希值为0,那么只需在0编号所对应的数据表中进行查找。
哈希(hash)函数又称为散列函数,计算键名的哈希值,就是将字典中的键名转换为对应的数字编号。
现在来写个简单的代码,来比较列表和字典的查找性能。
代码实例:
# __desc__ = 比较列表与字典的查找性能
# 通过import语句,可以导入Python的模块
# 导入time模块,执行time模块中的perf_counter方法来获取程序的执行时间。
import time
numbers = []
container = {}
# 使用for循环结构,分别往列表和字典中,添加1百万个数据
for _ in range(1, 1000000):
numbers.append(_)
container[_]=_
# 获取查找前的时间
start = time.perf_counter()
_ = 1000000 in numbers
# 获取查找后的时间
end = time.perf_counter()
# end-start就为查找过程中所耗费的查询时间
print("使用列表查找所消耗的时间{}".format(end-start))
start = time.perf_counter()
_ = 1000000 in container
end = time.perf_counter()
print("使用字典查找所消耗的时间{}".format(end - start))从程序的输出可知,字典的查找速度几乎是列表的100倍,数据量越大,查找性能越明显。为什么字典中的键必须是静态的数据类型?如果键名是静态的,不可变的,那么就能保证通过哈希函数计算时,得到的都是相同的哈希值。如果键名是动态的数据类型,意味着在这个数据类型的生命周期内,它的值是变化的,就不能保证计算得到的是相同的哈希值,所以键名必须是静态的数据类型,以保证其哈希值的唯一性。12.4.5 知识要点
(1) 字典类型的底层实现基于哈希表。(2) 在Python3.6版本前,字典中的键的输出顺序取决于键在哈希表中的存储顺序,从Python3.6版本以后,字典中的键的输出顺序按其插入的先后顺序进行输出。(3) 字典中的键的数据类型必须是静态的数据类型,迄今为止学过的静态的数据类型有:简单数据类型,字符串,元组。(4) 字典类型是基于哈希表实现的一种数据结构。(5) 哈希(hash)函数又称为散列函数,计算键名的哈希值,就是将字典中的键名转换为对应的数字编号。
12.4.6 最具实力的小班培训
薯条老师在广州有开设线下培训班,小班授课模式,一班最多6个人。也可一对一授课,全程帮助你学好计算机,实现高薪就业。不在广州的同学可提供住宿,也可以报名线上小班,用腾讯会议上直播课。
(1) Python后端工程师高薪就业班,月薪11K-18K,免费领取课程大纲
(2) Python高级爬虫+安卓逆向工程师就业班,月薪15K-25K,包拿Offer
(3) Python数据分析+商业分析+数据科学就业班,企业级项目实战,月薪10K-20K
(4) Python量化交易就业班,A股+期货+数字货币量化,月薪10K-40K
(5) Python机器学习+深度学习算法工程师,月薪20-50K
跟薯条老师学习的学生有拿到花生日记,林氏家居,南方电网,中国邮政集团,京东, 阿里等公司的offer, 学生的最低薪资有6K,最高薪资有18K, 平均就业薪资有11000。
扫码咨询薯条老师:



