教程引言:
系统地讲解计算机基础知识,Python的基础知识, 高级知识。关注微信公众号[薯条编程],免费领取Python电子书以及视频课程。
10.4.1 selenium的指纹检测
Selenium是一款web自动化测试工具,其底层使用JavaScript来对用户的操作进行模拟。selenium在驱动浏览器进行自动化操作时,会设置相关的DOM属性,其中一个比较典型的DOM属性是window.navigator.webdriver。
除了window.navigator.webdriver这一DOM属性,尚有数十个与selenium相关的指纹特征。读者可分析selenium源码或者在https://bot.sannysoft.com/页面所对应的js源码中找到与selenium相关的其它指纹信息。
现在来编写一段简单的js检测代码:
<script> alert(window.navigator.webdriver); </script>
将以上代码保存至html文件中(test_selenium.html),并用浏览器打开,打开后的浏览器页面如下图所示:
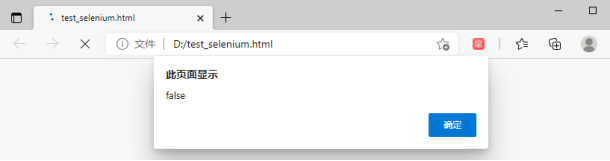
从提示信息可知,window.navigator.webdriver的属性值为false。现在通过selenium来访问该html文件,以下是代码实例:
from selenium import webdriver driver = webdriver.Firefox() driver.get(r"D:\\test_selenium.html")
下图所示为程序执行成功以后的浏览器页面:

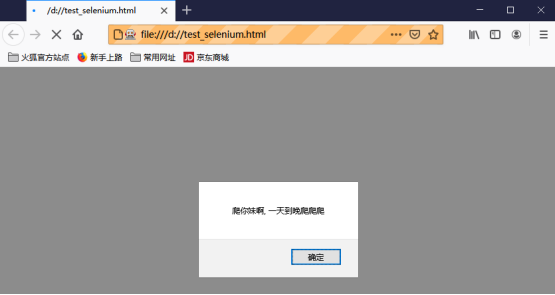
从js检测代码的提示信息可知,此时window.navigator.webdriver的属性值为true。window.navigator.webdriver为true,即表示客户端使用了selenium一类的自动化测试工具来驱动浏览器。基于这样的原理,目标站点利用selenium的相关指纹特征,便可轻松地检测出客户端是否为爬虫,一旦检测为爬虫,那么就采用更严格的反爬策略或直接禁止访问。
现在对js检测代码进行简单修改:
<script>
if (window.navigator.webdriver) {
alert("爬你妹啊, 一天到晚爬爬爬");
} else {
alert("你不是爬虫,你是个爬行动物");
}
</script>爬虫程序执行成功以后的浏览器窗口界面:
从以上例子可知,JS代码通过selenium暴露的指纹信息来进行检测,我们在思考反反爬的策略时,也应当从selenium运行时暴露的指纹特征入手,将这些指纹特征隐藏起来或关闭。在本节教程中,着重讲解两种反反爬策略,一是通过浏览器提供的配置选项来关闭指纹特征,一是通过mitmproxy等中间人代理来篡改页面的js检测脚本代码。
10.4.2 修改浏览器配置
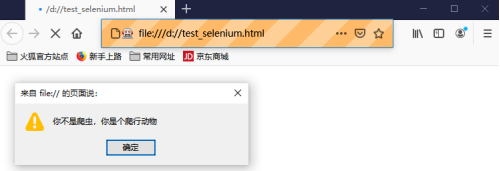
以火狐浏览器为例,将dom.webdriver.enabled设置为False,可隐藏window.navigator.webdriver这一DOM属性 ,以下为代码实例:
from selenium import webdriver
profile = webdriver.FirefoxProfile()
profile.set_preference("dom.webdriver.enabled", False)
driver = webdriver.Firefox(firefox_profile=profile)
driver.get(r"D:\\test_selenium.html")爬虫程序执行成功以后的浏览器窗口界面:
10.4.3 篡改JS检测代码
通过selenium打开某一个网页时,网页先由服务端响应给浏览器,浏览器再解析执行页面中的js代码。在这一过程中,我们可通过mitmproxy等中间人代理工具将服务端响应的页面数据截获下来,然后篡改其中的js检测代码,以达到反反爬的目的。为便于演示,需要读者先安装tornado模块,用来快速地搭建一个本地http服务器。
tornado模块的安装方法:在命令行中执行pip install tornado
安装成功以后,将以下代码保存至Python脚本文件app.py中:
import tornado.ioloop
import tornado.web
class TestSeleniumHandler(tornado.web.RequestHandler):
def get(self):
js_code = """
<script>
if (window.navigator.webdriver) {
alert("爬你妹啊, 一天到晚爬爬爬");
} else {
alert("你不是爬虫,你是个爬行动物");
}
</script>
"""
self.write(js_code)
if __name__ == '__main__':
app = tornado.web.Application([(r"/test_selenium", TestSeleniumHandler)])
app.listen(1986)
tornado.ioloop.IOLoop.current().start()进入windows命令行,切换到app.py所在的目录,执行python app.py命令以启动本地服务器。服务器启动成功以后,打开浏览器,然后在浏览器地址栏中输入http://127.0.0.1:1986/test_selenium,最后按下回车键:

接下来编写mitmproxy的http拦截脚本,脚本代码如下所示:
from mitmproxy import ctx
class ModifyJS:
def response(self, flow):
# 将响应的网页数据中的window.navigator.webdriver替换为false
flow.response.text = flow.response.text.replace("window.navigator.webdriver", "false")
addons = [
ModifyJS()
]将代码保存至Python脚本文件modify_js.py中,然后进入windows命令行,切换到modify_js.py所在的目录,并执行mitmdump -s modify_js.py:

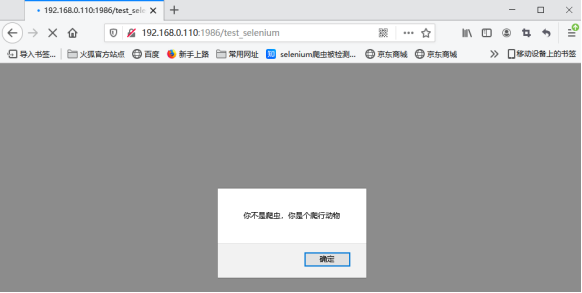
打开浏览器,在地址栏中输入http://<你本机的IP地址>:1986/test_selenium,并按回车键:
在页面中鼠标右键查看网页源代码:
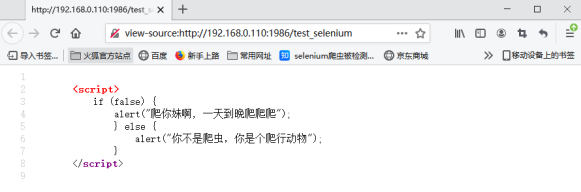
从页面的源码可知,网页的js代码已被篡改。接下来我们再修改爬虫程序中的selenium代码,将浏览器代理设置为mitmproxy服务器的地址:
from selenium import webdriver
profile = webdriver.FirefoxProfile()
profile.set_preference('network.proxy.type', 1)
# 将network.proxy.http设置为你本机的IP地址
profile.set_preference('network.proxy.http', '192.168.0.110')
# 将network.proxy.http_port设置为mitmproxy监听的端口
profile.set_preference('network.proxy.http_port', 8080)
profile.update_preferences()
driver = webdriver.Firefox(profile)
# IP需设置为你本机的IP地址
driver.get("http://192.168.0.110:1986/test_selenium")执行该爬虫程序,如出现下图所示的提示信息,则说明成功地实现了针对selenium指纹特征的反反爬。
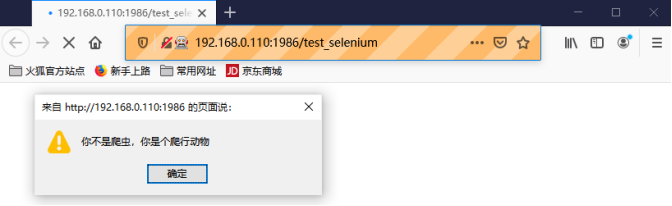
当然,实际的反爬场景要远比本节举的例子复杂,尤其是目标站点在对js代码进行了混淆的情况下,此时需要读者认真复习第八章中的内容,耐心地做好js逆向破解。
(1) Python后端工程师高薪就业班,月薪8K-15K,免费领取课程大纲
(2) Python爬虫工程师高薪就业班,年薪十万,免费领取课程大纲
(3) Java后端开发工程师高薪就业班,月薪8K-20K, 免费领取课程大纲
(4) Python大数据工程师就业班,月薪12K-25K,免费领取课程大纲
扫码免费领取学习资料:



