教程引言:
系统地讲解计算机基础知识,Python的基础知识, 高级知识。关注微信公众号[薯条编程],免费领取Python电子书以及视频课程。
10.1.1 User-Agent反爬
通过http协议的user-agent请求头字段来进行反爬,是一项简单而有效的反爬策略。user-agent简称UA,表示用户代理,通常用来指定浏览器及其版本信息。在第六章讲到了Python中的常用的http请求库,比如requests, 在使用requests发起请求时,http请求头的user-agent值默认为:
# {{version}}表示requests的版本号
python-requests/{{version}}
利用这样的特性,站点服务器通过检查UA值就可以判定是否为正常请求:如果为合规的UA值,就继续执行其它的反爬策略,否则直接判定为异常请求。对于这种针对UA的反爬措施,应对策略很简单,只需在发起请求时将默认的UA替换为合规的UA。合规的UA可直接在浏览器中获取,以火狐为例,在浏览器地址栏中执行about:support,可在页面中找到UA信息:

如果是chrome浏览器,可在地址栏中执行chrome://version/找到UA信息:
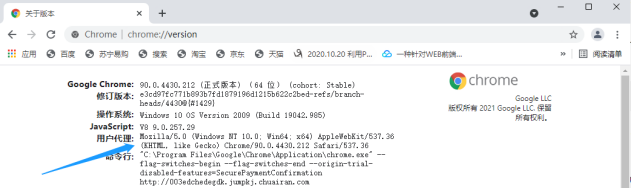
得到浏览器的UA以后,再将其复制下来,并修改爬虫代码。以requests为例,可通过关键字参数headers来定制请求头。headers接收一个字典类型的参数,键名表示HTTP请求头的字段名,键值为请求字段所对应的字段值。
代码实例-为爬虫程序设置UA:
import requests
# 以下url并不存在,读者可将其替换为真实的网页url
url = 'http://www.justtest.com'
# Chrome浏览器的UA
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:85.0) Gecko/20100101 Firefox/85.0 '
# 设置爬虫程序的UA,可在一定程度上防止被服务端反爬
headers = {'User-Agent': user_agent}
r = requests.get(url, headers=headers10.1.2 自定义请求头
一些站点还会通过一些扩展的http请求头来识别是否为爬虫,针对这种反爬策略,我们只需通过chrome,fiddlereverywhere等抓包工具对请求过程进行抓包,然后在爬虫代码中直接添加扩展的HTTP请求头字段。代码实例-为爬虫程序添加请求头:
import requests
# 以下url并不存在,读者可将其替换为真实的网页url
url = 'http://www.justtest.com'
# magic-no为扩展的请求头字段
headers = {'magic-no': 748201314}
r = requests.get(url, headers=headers)(1) Python后端工程师高薪就业班,月薪10K-15K,免费领取课程大纲
(2) Python爬虫工程师高薪就业班,年薪十五万,免费领取课程大纲
(3) Java后端开发工程师高薪就业班,月薪10K-20K, 免费领取课程大纲
(4) Python大数据工程师就业班,月薪12K-25K,免费领取课程大纲
扫码免费领取学习资料:



