广州番禺Python爬虫小班周末班培训
第四期线下Python爬虫小班周末班已经开课了,授课详情请点击:http://chipscoco.com/?id=232
9.2.1 mitmproxy简介
mitmproxy是一款用于中间人攻击的HTTP代理工具。所谓中间人攻击,简而言之,即截获正常的网络请求,并对请求进行篡改。当然,我们使用mitmproxy并不是用来对目标站点进行恶意攻击,而是利用mitprooxy工具的正向代理功能,来对网络请求进行截获、定制处理,从而辅助爬虫程序的开发。
9.2.2安装mitmproxy
直接在命令行中执行pip install mitmproxy来进行安装。模块安装成功以后,系统会额外安装mitmproxy, mitmdump, mitmweb三个命令。这三个命令都可用来启动mitmproxy服务,现在我们到windows命令行中分别执行这三个命令。
执行mitmproxy命令 :

从输出可知,mitmproxy命令并不支持windows系统。我们在使用mitmproxy服务时,只需启动mitmdump或mitmweb命令。执行mitmdump命令:

从输出可知,服务器启动以后,监听的端口号为8080。
执行mitmweb命令:

从输出可知,执行该命令以后同样会启动mitproxy服务,服务器监听的端口号为8080。同时系统会弹出浏览器,用户可在mitproxy的交互页面中实时看到已截获的HTTP请求。
9.2.3配置mitmproxy证书
通过mitmproxy拦截http请求,需要先配置mitmproxy的证书。在命令行中执行mitmdump命令以后,打开系统中的用户目录,在用户目录中可以见到一个.mitmproxy的子目录:
进入.mitmproxy目录即可找到mitmproxy的证书:
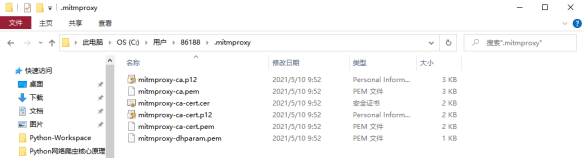
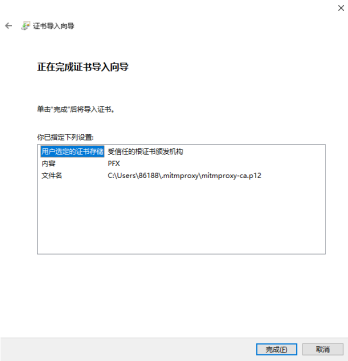
在目录中点击文件mitmproxy-ca.p12,即可导入证书。
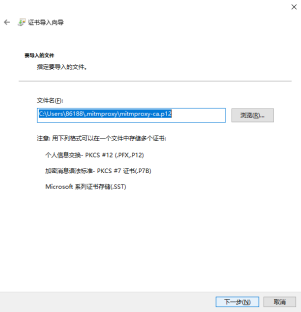
无需输入密码,直接点击下一步:
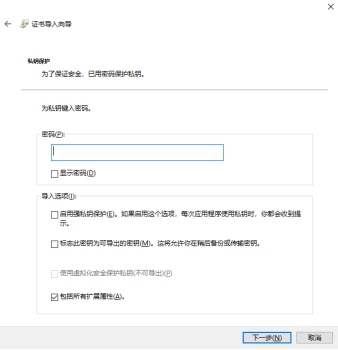
在下图所示的窗口中,勾选将所有的证书都放入下列存储:
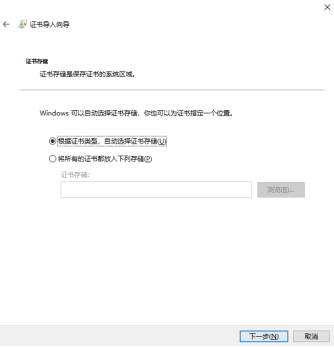
点击浏览按钮并在弹出的小窗口中选中受信任的根证书颁发机构:
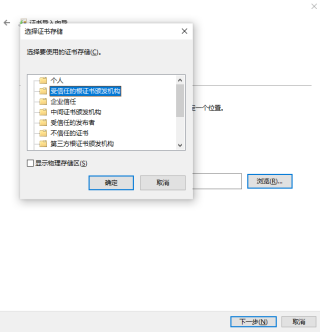
点击确定以及完成按钮,至此完成了证书的配置:
9.2.4 可拦截的HTTP事件
在mitmproxy的官方文档中可以找到mitmproxy所支持的事件,以下为对应的文档地址:
https://docs.mitmproxy.org/stable/addons-events/
本节教程主要讲解HTTP事件,以下为官方文档所提供的HTTP事件代码:
"""HTTP-specific events.""" import mitmproxy.http class Events: def http_connect(self, flow: mitmproxy.http.HTTPFlow): """ An HTTP CONNECT request was received. Setting a non 2xx response on the flow will return the response to the client abort the connection. CONNECT requests and responses do not generate the usual HTTP handler events. CONNECT requests are only valid in regular and upstream proxy modes. """ def requestheaders(self, flow: mitmproxy.http.HTTPFlow): """ HTTP request headers were successfully read. At this point, the body is empty. """ def request(self, flow: mitmproxy.http.HTTPFlow): """ The full HTTP request has been read. """ def responseheaders(self, flow: mitmproxy.http.HTTPFlow): """ HTTP response headers were successfully read. At this point, the body is empty. """ def response(self, flow: mitmproxy.http.HTTPFlow): """ The full HTTP response has been read. """ def error(self, flow: mitmproxy.http.HTTPFlow): """ An HTTP error has occurred, e.g. invalid server responses, or interrupted connections. This is distinct from a valid server HTTP error response, which is simply a response with an HTTP error code. """
Events类中的每一个对象方法用来处理一个特定的HTTP事件,比如http_connect表示收到了客户端的连接请求后被自动调用,request表示客户端的请求被完全读取以后被自动调用,response则表示来自服务端的响应被完全读取以后被自动调用。
在这些对象方法中,都定义了一个flow参数,flow参数用来传递mitmproxy.http.HTTPFlow对象。mitmproxy.http.HTTPFlow对象存储了http请求和响应的相关信息,其常用属性有request和response,前者存储了客户端的请求信息,后者则存储了服务端的响应信息。
mitmproxy.http.HTTPFlow.request对象的常用属性:
属性名 | 描述 |
url | 客户端请求的url |
host | 客户端请求的主机地址 |
scheme | http协议的scheme |
port | 请求的端口号 |
method | http请求方法 |
headers | http请求头 |
cookies | http请求cookie |
mitmproxy.http.HTTPFlow.response对象的常用属性:
属性名 | 描述 |
status_code | 服务端的响应状态码 |
headers | HTTP响应头 |
cookies | HTTP响应cookie |
text | 服务端响应的文本数据 |
9.2.5 编写http拦截脚本
我们使用mitmproxy来辅助爬虫程序的开发,主要是对客户端的http请求和服务端的响应进行拦截并修改。那么,该如何通过mitmproxy对请求和响应进行拦截处理?以下为mitmproxy官方文档提供的拦截脚本代码实例:
"""
Basic skeleton of a mitmproxy addon.
Run as follows: mitmproxy -s anatomy.py
"""
from mitmproxy import ctx
class Counter:
def __init__(self):
self.num = 0
def request(self, flow):
self.num = self.num + 1
ctx.log.info("We've seen %d flows" % self.num)
addons = [
Counter()
]以上代码表示对http的request请求进行了拦截,每拦截一次就对num加1,同时执行ct.log.info方法在命令行输出拦截的次数。该代码最核心的是全局变量addons, mitmproxy在加载自定义的拦截脚本时,会自动执行addons中的每一个addon对象的事件处理方法。比如Counter对象就是一个addon,当客户端的请求被完全读取以后,mitmproxy会自动执行Counter对象的request方法。
执行以上代码,需要先配置浏览器的代理为mitmproxy服务器的地址,然后在windows命令行中执行mitmdump -s xxx.py,xxx.py表示上述代码所在的Python脚本文件。进入windows命令行并执行mitmdump,可以获得mitmproxy服务器的地址:

从输出可知地址为本地,端口为8080,本地的ip地址可以在命令行中执行ipconfig来获取:

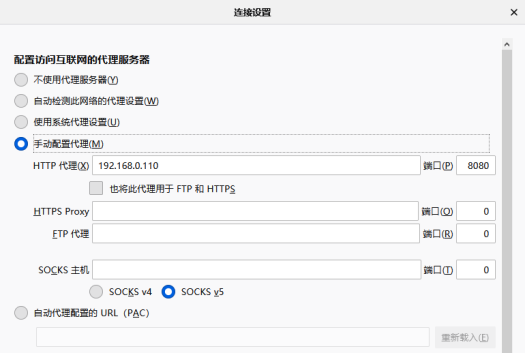
有了ip地址和端口号以后,再打开浏览器进行配置。以火狐浏览器为例,点击选项并找到网络设置,然后点击设置进行配置:

在连接设置中选中手动配置代理,并输入http代理的地址和端口号:
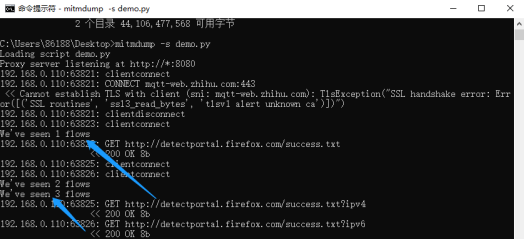
配置完毕以后将代码写入到demo.py,并在windows命令行中执行mitmdump -s demo.py。
随后打开浏览器并访问任意网页,此时在命令行中看到了拦截后的输出信息,如下图的蓝色箭头所示:
更多的mitmproxy的拦截代码实例,同学们可访问mitmproxy的官方文档,以下为文档地址:
https://docs.mitmproxy.org/stable/addons-examples/
文档中提供了以下几个与http拦截有关的代码实例:

以上代码实例不再一一赘述,现在仅以http-add-header.py来进行讲解。
http-add-header.py中的代码:
"""Add an HTTP header to each response.""" class AddHeader: def __init__(self): self.num = 0 def response(self, flow): self.num = self.num + 1 flow.response.headers["count"] = str(self.num) addons = [ AddHeader() ]
(1) Python后端工程师高薪就业班,月薪10K-15K,免费领取课程大纲
(2) Python爬虫工程师高薪就业班,年薪十五万,免费领取课程大纲
(3) Java后端开发工程师高薪就业班,月薪10K-20K, 免费领取课程大纲
(4) Python大数据工程师就业班,月薪12K-25K,免费领取课程大纲
扫码免费领取学习资料:



