广州番禺Python爬虫小班周末班培训
第四期线下Python爬虫小班周末班已经开课了,授课详情请点击:http://chipscoco.com/?id=232
9.1.1 Selenium简介
在第八章讲到了js逆向,做逆向耗时耗力,繁琐且复杂,而且做逆向破解需要有一定的js基础,源码阅读能力,以及逆向思维,对于基础薄弱的初学者来说,很难在短时间内掌握其关窍。
那么,有没有这样的一种辅助爬虫的工具,不用分析加密参数,只需模拟用户在浏览器中的操作,比如模拟用户在页面中的输入,在页面中的点击等,再直接抓取到页面数据?本节介绍的Selenium就是这样的一款爬虫辅助工具,借助Selenium, 使得爬虫程序能驱动浏览器,模拟出用户的真实操作。
Selenium是一个web自动化测试工具,其底层使用JavaScript来对用户的操作进行模拟。我们在编写爬虫程序时,只需调用Selenium提供的方法,就可以驱动浏览器,模拟出用户的真实行为,再通过浏览器对象直接获取页面的数据。
9.1.2 Selenium环境搭建
(1) 安装selenium模块
直接在命令行中通过pip进行安装:
pip install selenium
(2) 配置浏览器驱动
通过selenium驱动浏览器,需要先配置浏览器驱动。chrome浏览器驱动的下载地址:
https://npm.taobao.org/mirrors/chromedriver/
火狐浏览器驱动的下载地址:
https://github.com/mozilla/geckodriver/releases
同学们在下载浏览器驱动时,需按浏览器对应的版本进行下载。下载完毕后,再将浏览器驱动所在的目录的绝对路径添加至环境变量PATH中。在命令行中执行sysdm.cpl,会弹出一个系统属性窗口:
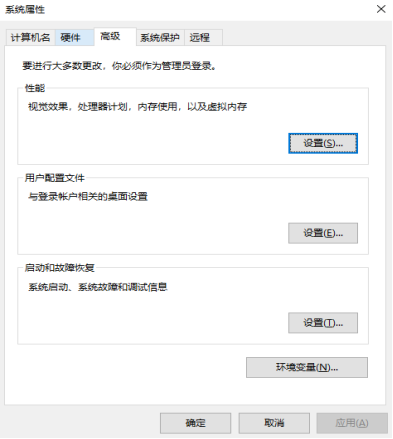
在窗口中分别点击高级、环境变量,会弹出以下子窗口:
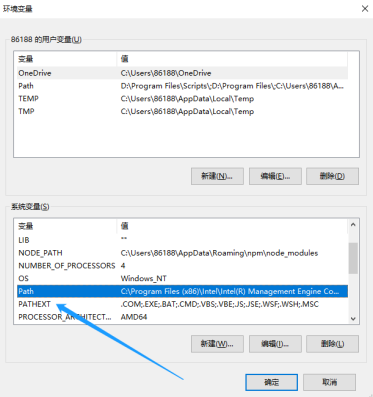
双击系统变量Path又会弹出一个配置窗口:
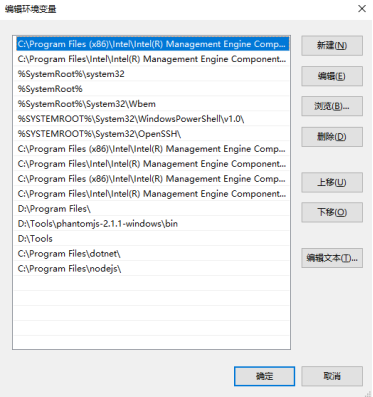
在该窗口中点击新建即可将浏览器驱动所在的目录的绝对路径添加至环境变量PATH。配置完毕以后再进入windows命令行执行chromedriver(chrome浏览器的驱动)或geckodriver(火狐浏览器的驱动):

9.1.3 Selenium快速入门
(1) 构造浏览器对象
通过selenium.webdriver中的Chrome构造谷歌浏览器对象:
from selenium import webdriver chrome = webdriver.Chrome()
通过selenium.webdriver中的Firefox构造火狐浏览器对象:
from selenium import webdriver firefox = webdriver.Firefox()
执行以上代码以后,系统会自动弹出一个空白页面的浏览器:
(2) 访问网页,获取源码
通过浏览器对象的get方法来发起请求,请求成功以后再通过浏览器对象的page_source属性来获取网页源码:
from selenium import webdriver
firefox = webdriver.Firefox()
# 访问百度首页
firefox.get('https://www.baidu.com')
# 通过page_source属性获取网页源码
print(firefox.page_source)执行以上代码以后,系统会弹出一个浏览器,浏览器显示的正是百度首页:
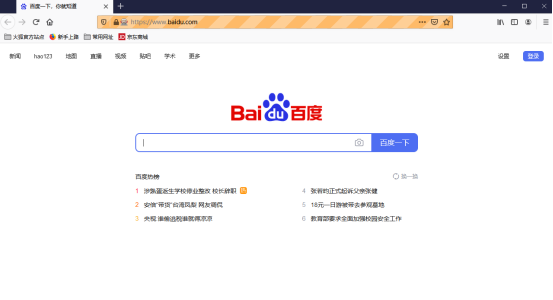
(3) 模拟用户行为
通过selenium驱动浏览器并打开指定的网页以后,该如何模拟用户的行为?以百度搜索为例,打开网页以后,需要先定位到网页中的标签对象,再通过标签对象的send_keys方法来模拟输入, 通过click方法来模拟用户点击。selenium提供了多种定位方法,在本节教程中主要讲解以下三种常用的定位方法:
常用定位方法 | 描述 |
find_element_by_id(id_) | 根据HTML标签对象的id进行定位 |
find_element_by_class_name(name) | 根据HTML标签对象的class进行定位 |
find_element_by_name(name) | 根据HTML标签对象的属性名进行定位 |
通过标签对象来模拟用户在浏览器操作的常用方法:
常用浏览器操作 | 描述 |
send_keys(value) | 模拟用户的输入 |
clear() | 清空用户的输入 |
click() | 模拟用户的点击 |
submit() | 模拟用户提交表单 |
代码实例-模拟百度搜索:
from selenium import webdriver
import time
browser = webdriver.Firefox()
# 访问百度首页
browser.get('https://www.baidu.com')
# 根据id定位到百度首页中的输入框
input = browser.find_element_by_id('kw')
# 在输入框中输入薯条老师
input.send_keys('薯条老师')
# 根据id定位到首页中的搜索按钮
search = browser.find_element_by_id('su')
# 执行click方法,模拟用户的点击事件
search.click()
# 执行time.sleep方法模拟用户在页面停留
time.sleep(3)
# 清空页面输入
input.clear()
input.send_keys('薯条编程')
search.click()程序执行成功以后,系统会弹出浏览器,并自动在输入框中输入薯条老师,点击搜索按钮进行搜索:
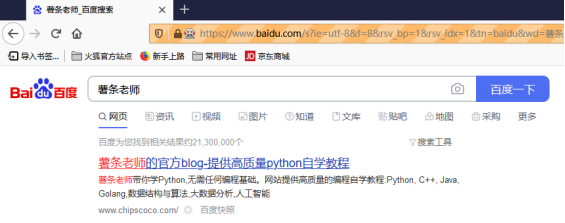
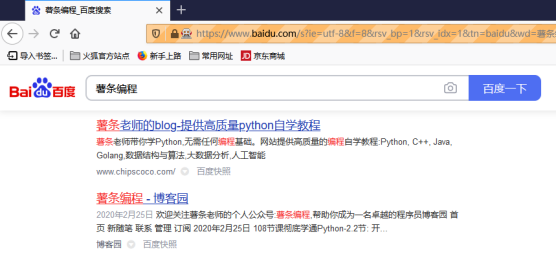
9.1.4 Selenium进阶用法
(1) 等待事件
当定位的元素未被载入至页面中时,在程序中对该元素进行操作会抛出
ElementNotVisibleException异常。此时可通过selenium提供的等待事件,仅当页面中存在此元素时才继续进行操作。
selenium提供了两类等待事件,一类是隐式等待:
隐式等待 | 描述 |
implicitly_wait(seconds) | 等待指定的秒数,直到页面元素可用或超时。 |
一类是显式等待:通过selenium的WebDriverWait与ExpectedCondition进行实现。WebDriverWait用来指定等待的时间,ExpectedCondition则用来指定等待的预期条件。在selenium官方文档中列出了常用的预期条件,以下为文档地址:
https://python-selenium-zh.readthedocs.io/zh_CN/latest/5.Waits/
代码实例-模拟百度搜索:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Firefox()
# 访问百度首页
browser.get('https://www.baidu.com')
try:
# 等待页面中出现id为kw的元素,等待时间为5秒
input = WebDriverWait(browser,5).until(EC.presence_of_element_located((By.ID,'kw')))
# 页面中出现id为kw的元素后才模拟用户的输入
input.send_keys('薯条老师')
# 根据id定位到首页中的搜索按钮
search = browser.find_element_by_id('su')
# 执行click方法,模拟用户的点击事件
search.click()
finally:
browser.quit()(2) 鼠标操作
通过selenium,也可以模拟鼠标的移动,点击,拖拽等操作。模拟鼠标操作需要先构造ActionChains对象:
from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains # 构造火狐浏览器对象 firefox = webdriver.Firefox() # 构造ActionChains对象 action_chains = ActionChains(firefox)
模拟鼠标操作的常用方法:
常用鼠标操作 | 描述 |
move_to_element(to_element) | 鼠标移动至to_element指向的元素 |
move_by_offset(xoffset, yoffset) | 将鼠标从xoffset位置移动到yoffset位置 |
click(on_element=None) | 点击on_element所指向的页面元素 |
click_and_hold(on_element=None) | 鼠标左击on_element元素,并一直保持 |
drag_and_drop(source, target) | 鼠标左击source元素,并移动至target元素 |
通过ActionChains模拟鼠标的一系列操作,最终还需执行ActionChains提供的perform方法来执行行为链。
代码实例-模拟鼠标移动:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
browser = webdriver.Firefox()
browser.get('
# 等待页面中出现class为sinup的元素,等待时间为5秒
login = WebDriverWait(browser,5).until(EC.presence_of_element_located((By.CLASS_NAME,'sinup')))
actions = ActionChains(browser)
# 将鼠标移动至登录按钮并点击
actions.move_to_element(login).click(login).perform()9.1.5启动无头浏览器
通过selenium驱动浏览器进行自动化操作时,在缺省情况下会弹出浏览器的GUI,以下是一段代码实例:
from selenium import webdriver
firefox = webdriver.Firefox()
firefox.get('http://www.chipscoco.com')执行以上代码以后,系统会弹出火狐浏览器的GUI窗口:
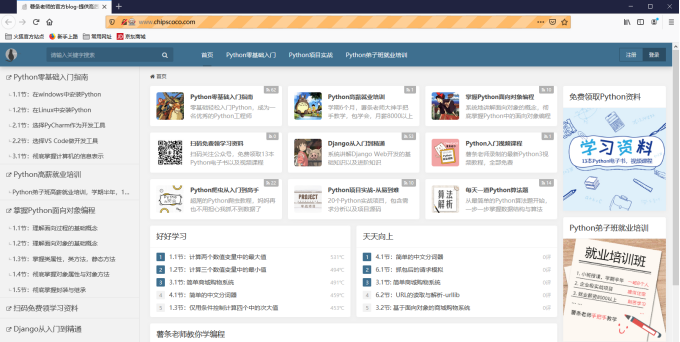
在浏览器窗口中可以直观地看到程序的自动化操作,但在大部分使用场景中,我们是不需要浏览器窗口的,只需驱动浏览器内核来完成爬虫的自动化操作。通过在selenium中设置浏览器的无头模式,可以快速地启动无头浏览器,以下是启动火狐无头浏览器的代码实例:
from selenium import webdriver
options = webdriver.FirefoxOptions()
# 配置无头模式
options.add_argument("--headless")
options.add_argument("--disable-gpu")
driver = webdriver.Firefox(options=options)
driver.get("http://www.chipscoco.com")
driver.close()启动谷歌无头浏览器的代码实例:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
# 配置无头模式
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)
driver.get("http://www.chipscoco.com")
driver.close()9.1.6 Selenium爬虫实战
在本节的爬虫实战中,通过selenium来模拟用户登录薯条老师的官方博客www.chipscoco.com。在模拟登录之前,同学们需要先注册一个账号,以下为注册页地址:
http://chipscoco.com/?Register
代码实例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
browser = webdriver.Firefox()
browser.get('http://www.chipscoco.com')
login =
# 等待页面中出现class为sinup的元素,等待时间为5秒
WebDriverWait(browser,5).until(EC.presence_of_element_located((By.CLASS_NAME,'sinup')))
actions = ActionChains(browser)
# 将鼠标移动至登录按钮并点击
actions.move_to_element(login).click(login).perform()
# 找到id为edtUserName的页面元素,该html元素用来输入用户名
username_input = browser.find_element_by_id('edtUserName')
username_input.send_keys("替换成你的登录账号")
# 找到id为edtPassWord的页面元素,该html元素用来输入登录密码
password_input = browser.find_element_by_id('edtPassWord')
password_input.send_keys("替换为你的登录密码")
# 找到id为loginbtnPost的页面元素,该html元素用来提交登录请求
submit_button = browser.find_element_by_id('loginbtnPost')
# 点击登录按钮
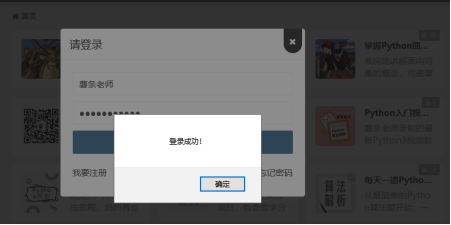
submit_button.click()程序执行以后,selenium会驱动浏览器并模拟用户登录薯条老师的官方博客chipscoco,如下图所示:
(1) Python后端工程师高薪就业班,月薪10K-15K,免费领取课程大纲
(2) Python爬虫工程师高薪就业班,年薪十五万,免费领取课程大纲
(3) Java后端开发工程师高薪就业班,月薪10K-20K, 免费领取课程大纲
(4) Python大数据工程师就业班,月薪12K-25K,免费领取课程大纲



